AlphaGo Zero的强化学习
上面提到AlphaGo使用了一个神经网络,这是怎么做到的?
DeepMind使用了一个新的神经网络fθ,θ是参数。这个神经网络将原始棋盘表征s(落子位置和过程)作为输入,输出落子概率(p, v)= fθ(s)。这里的落子概率向量p表示下一步的概率,而v是一个标量估值,衡量当前落子位置s获胜的概率。
这个神经网络把之前AlphaGo所使用的策略网络和价值网络,整合成一个单独的架构。其中包含很多基于卷积神经网络的残差模块。
AlphaGo Zero的神经网络,使用新的强化学习算法,自我对弈进行训练。在每个落子位置s,神经网络fθ指导进行MCTS(蒙特卡洛树)搜索。MCTS搜索给出每一步的落子概率π。通常这种方式会选出更有效的落子方式。
因此,MCTS可以被看作是一个强大的策略提升operator。这个系统通过搜索进行自我对弈,使用增强的MCTS策略决定如何落子,然后把获胜z作为价值样本。
这个强化学习算法的主要理念,实在策略迭代过程中,反复使用这些这些搜索operator:神经网络的参数不断更新,让落子概率和价值(P,v)=fθ(s)越来越接近改善后的搜索概率和自我对弈赢家(π, z)。这些新参数也被用于下一次的自我对弈迭代,让搜索变得更强大。整个过程如下图所示。
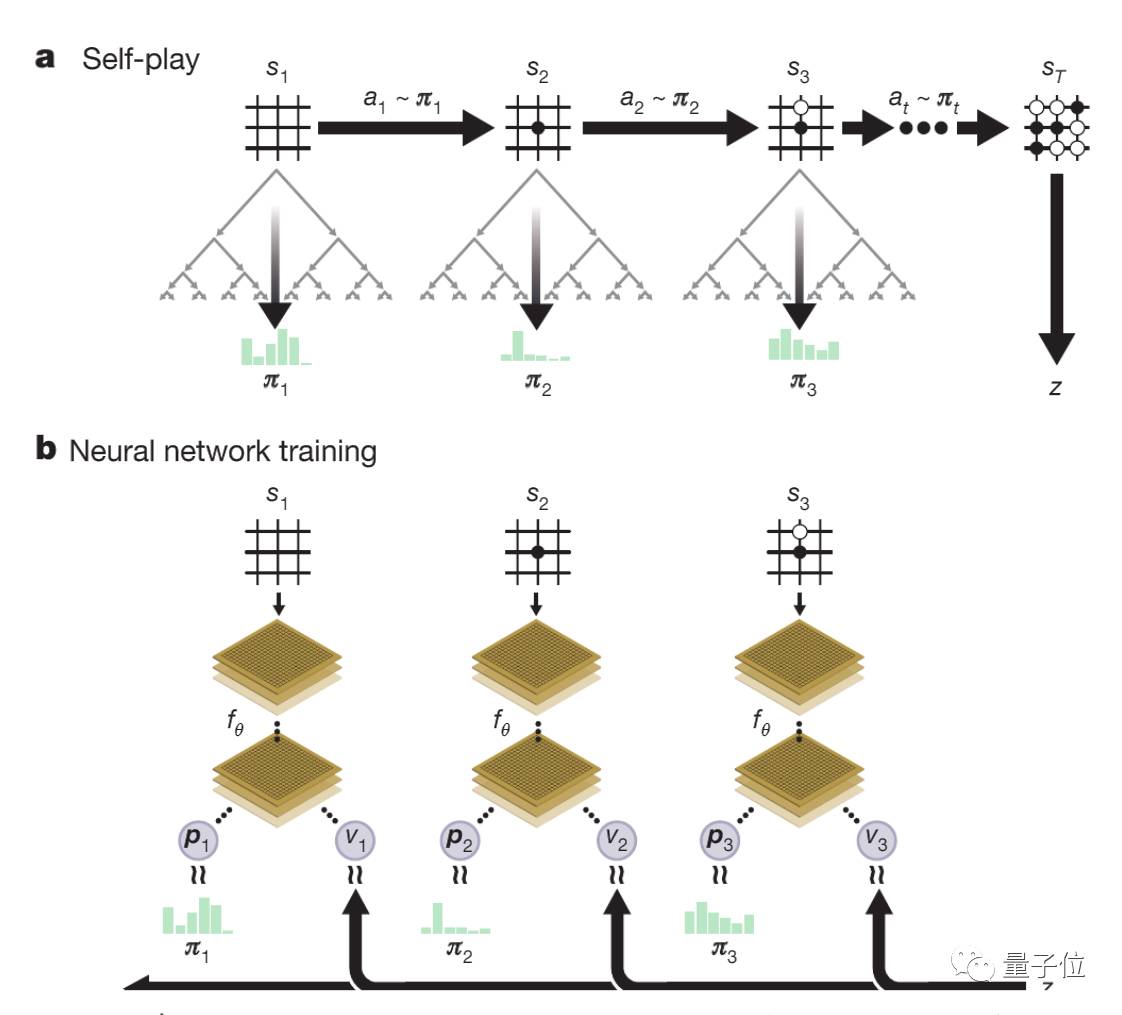
上图解释了AlphaGo Zero中的自我对弈强化学习。图a展示了程序的自我对弈过程。程序在从s1到st的棋局中进行自我对弈,在任意位置st,程序会用最新的神经网络fθ来执行MCTS αθ,根据MCTS计算出的搜索概率at∼πt选择落子位置,根据游戏规则来决定最终位置sT,并计算出胜者z。
图b展示了AlphaGo Zero中的神经网络训练过程,神经网络以棋盘位置st为输入,将它和参数θ通过多层CNN传递,输出向量Pt和张量值vt,Pt表示几步之后可能的局面,vt表示st位置上当前玩家的胜率。为了将Pt和搜索概率πt的相似度最大化,并最小化vt和游戏实际胜者z之间的误差,神经网络的参数θ会不断更新,更新后的参数会用到如图a所示的下一次自我对弈迭代中。
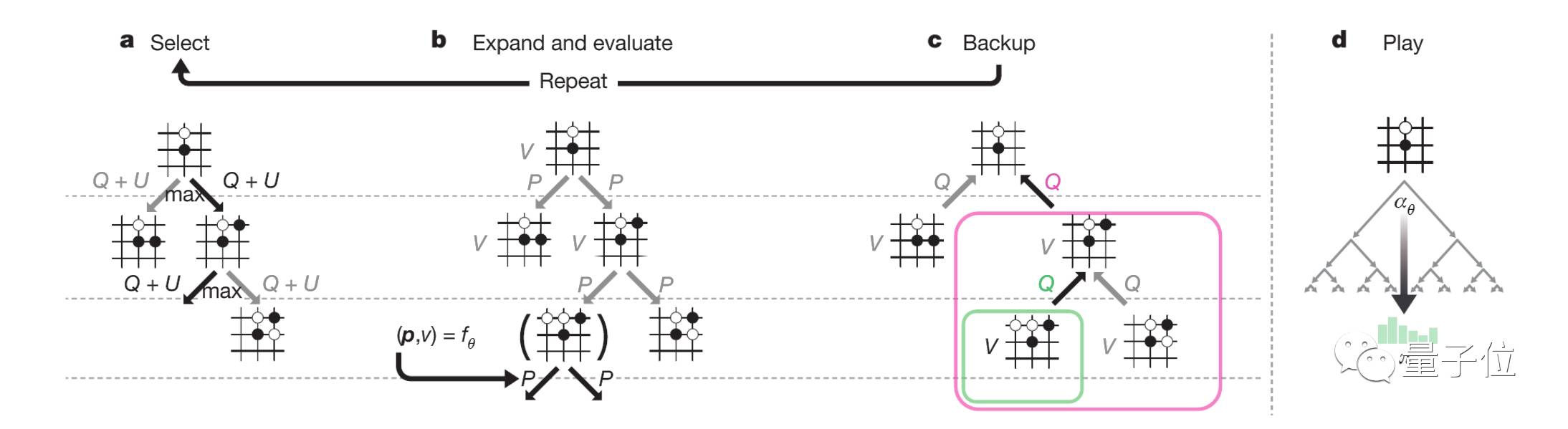
AlpaGo Zero中的MCTS结构如上图所示,从图a显示的选择步骤可以看出,每次模拟都会通过选择最大行为价值Q的边缘,加上置信区间上限U来遍历树,U取决于存储先验概率P和访问次数N。
图b显示,叶节点扩展和相关位置s的评估都是通过神经网络(P(s, ·),V(s)) = fθ(s)实现的,P的向量值存储在s的出口边缘。





















 营业执照公示信息
营业执照公示信息